一、kafka可以做什么
消息队列
类似一个消息系统,读写流式的数据。还有消息顺序性保障,以及回溯消费的功能。
存储系统
安全的将流式的数据存储在一个分布式,有副本备份,容错的集群。将消息持久化到磁盘,得益于顺序写入磁盘持久化消息包和多副本机制。
流式处理平台
编写可扩展的流处理应用程序,用于实时事件响应的场景。可以为流行的流式处理框架提供可靠的数据来源。
二、对比Kafka和RabbitMQ
| 功能项 | Kafka(1.1.0版本) | RabbitMQ(3.6.10版本) |
|---|---|---|
| 优先级队列 | 不支持 | 支持。 建议优先级大小设置在0-10之间。 |
| 延迟队列 | 不支持 | 支持 |
| 死信队列 | 不支持 | 支持 |
| 重试队列 | 不支持 | 不支持。 RabbitMQ中可以参考延迟队列实现一个重试队列,二次封装比较简单。 如果要在Kafka中实现重试队列,首先得实现延迟队列的功能,相对比较复杂。 |
| 消费模式 | 推模式 | 推模式+拉模式,业务中更多的是用推模式 |
| 广播消费 | 支持。 Kafka对于广播消费的支持相对而言更加正统。 |
支持。 但力度较Kafka弱。 |
| 消息回溯 | 支持。 Kafka支持按照offset和timestamp两种维度进行消息回溯。 |
不支持。 RabbitMQ中消息一旦被确认消费就会被标记删除。 |
| 消息堆积 | 支持 | 支持。 一般情况下,内存堆积达到特定阈值时会影响其性能,但这不是绝对的。 如果考虑到吞吐这因素,Kafka的堆积效率比RabbitMQ总体上要高很多。 |
| 持久化 | 支持 | 支持 |
| 消息追踪 | 不支持。 消息追踪可以通过外部系统来支持,但是支持粒度没有内置的细腻。 |
支持。 RabbitMQ中可以采用Firehose或者rabbitmq_tracing插件实现。 不过开启rabbitmq_tracing插件件会大幅影响性能,不建议生产环境开启, 反倒是可以使用Firehose与外部链路系统结合提供高细腻度的消息追踪支持。 |
| 消息过滤 | 客户端级别的支持。 Java一般在拦截器中过滤,PHP没有。 |
不支持。 但是二次封装一下也非常简单。 |
| 多租户 | 不支持 | 支持 |
| 多协议支持 | 只支持定义协议,目前几个主流版本间存在兼容性问题。 | RabbitMQ本身就是AMQP协议的实现,同时支持MQTT、STOMP等协议。 |
| 跨语言支持 | 采用Scala和Java编写,支持多种语言的客户端。 | 采用Erlang编写,支持多种语言的客户端。 |
| 流量控制 | 支持client和user级别,通过主动设置可将流控作用于生产者或消费者。 | RabbitMQ的流控基于Credit-Based算法,是内部被动触发的保护机制,作用于生产者层面。 |
| 消息顺序性 | 支持单分区(partition)级别的顺序性。 | 顺序性的条件比较苛刻,需要单线程发送、单线程消费并且不采用延迟队列、 优先级队列等一些高级功能,从某种意义上来说不算支持顺序性。 |
| 安全机制 | (TLS/SSL、SASL)身份认证和(读写)权限控制 | 与Kafka相似 |
| 幂等性 | 支持单个生产者单分区单会话的幂等性。 | 不支持 |
| 事务性消息 | 支持 | 支持 |
消费模式
消费模式分为推(push)模式和拉(pull)模式。推模式是指由Broker主动推送消息至消费端,实时性较好,不过需要一定的流控机制(flow control)来确保服务端推送过来的消息不会压垮消费端。
而拉模式是指消费端主动向Broker端请求拉取(一般是定时或者定量)消息,实时性较推模式差,但是可以根据自身的处理能力而控制拉取的消息量。
RabbitMQ一般采用推(push)模式,同时在消费端,使用qos来保证同步给Broker消费能力。Kafka一般采用拉(pull)模式。
三、消息可靠性和可用性保证
从狭义的角度来说,分布式系统架构是一致性协议理论的应用实现,对于消息可靠性和可用性而言也可以追溯到消息中间件背后的一致性协议。
对于Kafka而言,其采用的是类似PacificA的一致性协议,通过ISR(In-Sync-Replica)来保证多副本之间的同步,并且支持强一致性语义(通过acks实现)。
对应的RabbitMQ是通过镜像环形队列实现多副本及强一致性语义的。多副本可以保证在master节点宕机异常之后可以提升slave作为新的master而继续提供服务来保障可用性。
Kafka设计之初是为日志处理而生,给人们留下了数据可靠性要求不要的不良印象,但是随着版本的升级优化,其可靠性得到极大的增强,详细可以参考KIP101。
就目前而言,在金融支付领域使用RabbitMQ居多,而在日志处理、大数据等方面Kafka使用居多,随着RabbitMQ性能的不断提升和Kafka可靠性的进一步增强,相信彼此都能在以前不擅长的领域分得一杯羹。
四、kafka入门
广播消费
消息一般有两种传递模式:点对点(P2P,Point-to-Point)模式和发布/订阅(Pub/Sub)模式。
对于点对点模式而言,消息被消费以后,队列中不会再存储,所以消息消费者不可能消费到已经被消费的消息。虽然队列可以支持多个消费者,但是一条消息只会被一个消费者消费。
发布订阅模式定义了如何向一个内容节点发布和订阅消息,这个内容节点称为主题(topic),主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,而消息订阅者则从主题中订阅消息。
主题使得消息的订阅者与消息的发布者互相保持独立,不需要进行接触即可保证消息的传递,发布/订阅模式在消息的一对多广播时采用。
Kafka和RabbitMQ中的消息模式
RabbitMQ是一种典型的点对点模式,而Kafka是一种典型的发布订阅模式。
但是RabbitMQ中可以通过设置交换器类型来实现发布订阅模式而达到广播消费的效果,Kafka中也能以点对点的形式消费,你完全可以把其消费组(consumer group)的概念看成是队列的概念。
不过对比来说,Kafka中因为有了消息回溯功能的存在,对于广播消费的力度支持比RabbitMQ的要强。
Kafka中核心概念
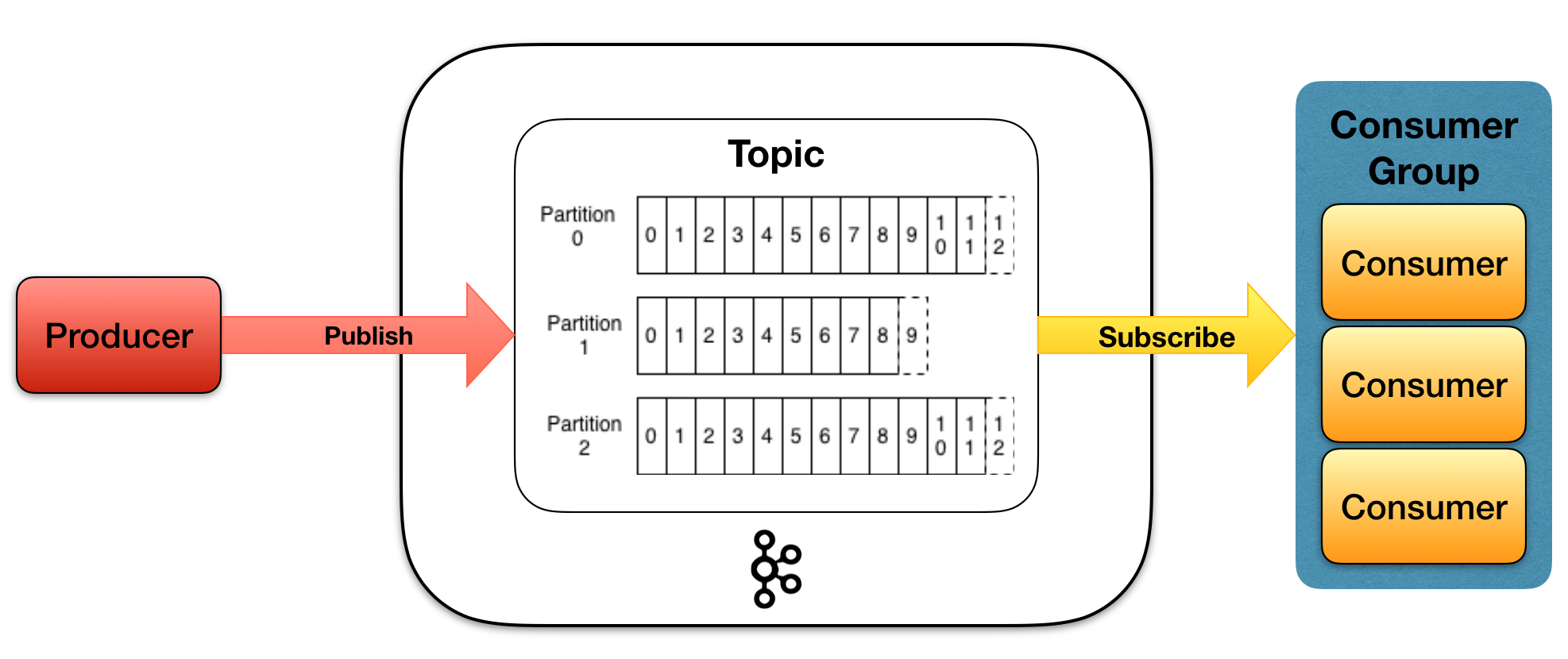
- producer 生产者
- topic 话题,消息源的不同分类
- partition 分区,话题topic物理上分组,一个topic中有多个partition,每个partition都是有序队列,队列中每一个消息都有唯一的offset
- consumer group 消费者组,可以并行消费topic中partition的消息
- consumer 消费者
类比RabbitMQ中核心概念(消息路由角度)
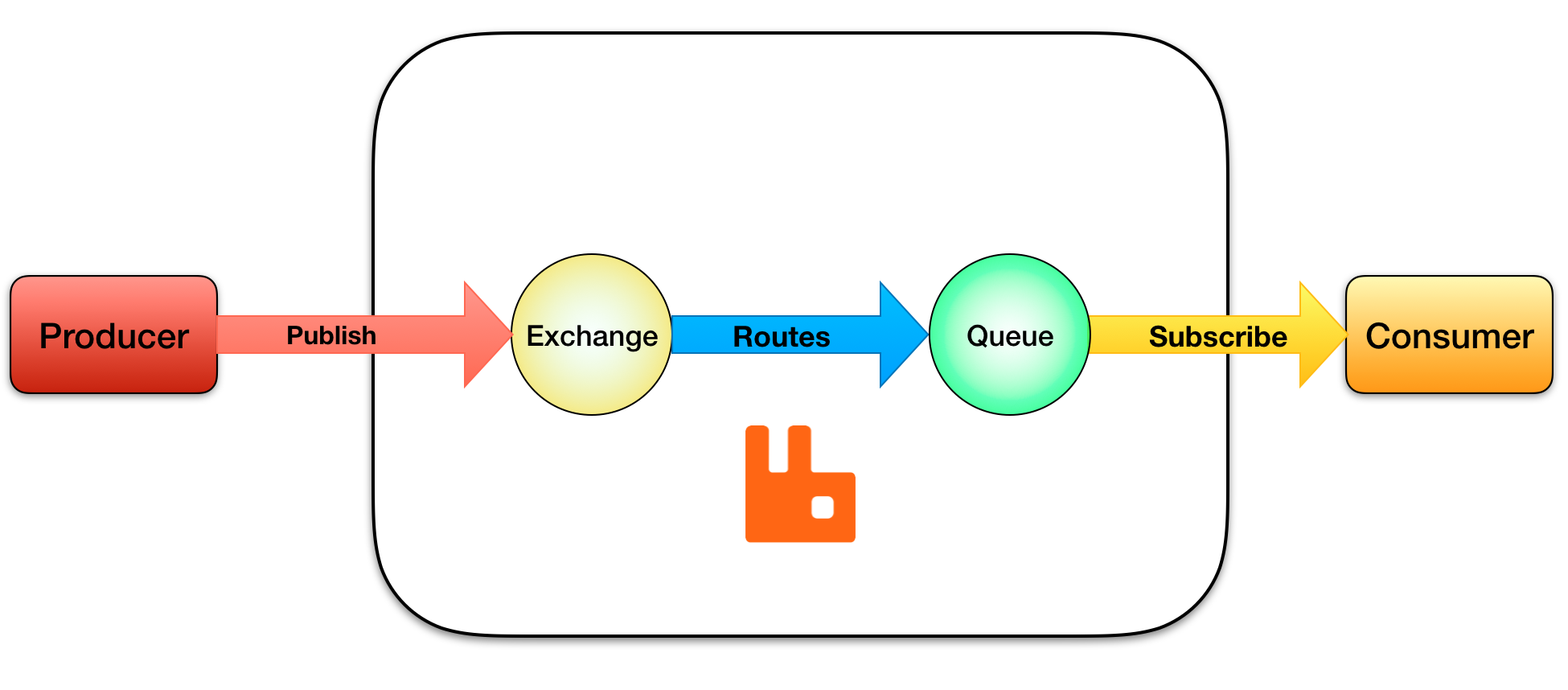
- kafka producer == rabbitmq producer
- kafka topic == rabbitmq exchange
- kafka consumer group == rabbitmq queue
- kafka consumer == rabbitmq consumer
五、Kafka开发需要关注的地方
如何提高consumer消费速度
对于官方提供Java的client,可以从不同粒度考虑,提高消费能力
- 选择合适的partition数量和对应的consumer数量
- consumer中,多线程处理消息的拉取poll()逻辑,不过该方案client和server中间会创建多个连接资源,本质上和多进程是一样的
- consumer中,多线程处理消息的消费逻辑
对于PHP语言来说,暂时调研发现,只好从选择合适的partition数量和对应的consumer数量入手提高消费能力
如何保证消息不重复消费
消息的不重复消费,其实就是同一个消息,在正常情况下,不会被consumer消费2次。
Kafka中有一个consumer offset概念,来保存消费者最终消费的进度。kafka中提供了2种方式,提交consumer offset。
- 自动提交。config中配置 enable.auto.commit=true,更新的频率根据参数 auto.commit.interval.ms 决定,这种方式称为 at most once。fetch到了消息包之后,就可以更新offset,不管是否已经消费成功。
- 手动提交。设置 enable.auto.commit=false,这种方式称为 at least once。等消费完成,手动调用commitSync(),更新offset。如果消费失败,则offset也不会更新,此条消息会被重复消费一次。
单进程,单线程,读取一条消息消费完成就提交一次offset,可以保证消息不会重复消费,但是也是消费性能最差的一种。
后续有机会,可以再分析手动提交consumer offset存在的一些问题以及解决方案。
何时创建Topic和Partition
创建topic和partition,一般有2个地方可以
- server端,运维创建
- client端,服务容器启动后
对于PHP脚本型语言来说,没有服务容器概念,比较建议在server端,由运维创建。
PHP使用RabbitMQ,在consumer中创建exchange和queue,其实是不合理的
- 一是consumer承载了初始化和消费消息两部分逻辑
- 二是脚本注册过于简单,后期运维麻烦。
PHP是使用c扩展还是使用composer包
c扩展
Qihoo360/kafkabridge
- 支持多种语言:c++/c、php、python、golang, 且各语言接口完全统一;
- 接口少,简单易用;
- 针对高级用户,支持通过配置文件调整所有的librdkafka的配置;
- 在非按key写入数据的情况下,尽最大努力将消息成功写入;
- 支持同步和异步两种数据写入方式;
- 在消费时,除默认自动提交offset外,允许用户通过配置手动提交offset;
- 在php-fpm场景中,复用长连接生产消息,避免频繁创建断开连接的开销;
composer包
weiboad/kafka-php
- 代码最后更新时间 2018年05月31日
- v0.2.0.8 2017-10-23 09:33 UTC
rapide/laravel-queue-kafka
- 代码最后更新时间 2019年03月22日
- 1.0 2018-11-10 14:58 UTC
现阶段(2019年04月)的PHP部署架构,依赖的是php-fpm模型。
虽然在php-fpm中复用长连接比较美好,但是我们的所有业务一共有超过10台机器部署,每台fpm配置最大子进程数=300,没有连接池的情况下,一共会产生超过3000的连接数,不管后面连接的是RabbitMQ、Kafka、Redis还是MySQL,都会存在问题,这方面仍需要继续深挖调研。